
Yes Steve Model Java层分析报告
2026-05-07摘要
继 YSMParser 完成对 .ysm 格式的解密之后,本文记录了我们对YSM Mod本体的逆向分析过程。YSM自LegacyYSM开源后长期处于闭源+混淆+Native保护的三重黑盒状态,没有任何公共接口可供调用,对外完全不可见。我们从Jar包开始反混淆和反编译并使用JNI Hook + IDA静态分析的组合,逐个还原了Native层的核心方法,包括客户端初始化、模型渲染(含SSE矩阵运算与骨骼蒙皮)、模型加载(含YSMParser集成)和网络通信。最终我们成功在不依赖原始DLL的情况下让YSM Mod正常启动并进入游戏。
引言
在YSMParser项目上线之后,我们现在可以解密被YSM的DRM系统加密的.ysm模型了。
虽然我们已经完全理解了他的DRM是如何工作的,然而我们对YSM Mod内部是如何工作的,如何渲染的,以及这个DRM系统和Java层是如何交互的这几个问题一概不知,YSM自LegacyYSM开源之后一直处于闭源+混淆的状态,且没有任何公共接口可以调用,这让YSM Mod自身成为了一个黑盒,而为了探究他的工作方式,我们对他的Mod展开了研究。
分析Jar包
使用Recaf对Jar进行简单反编译,可以看到所有的符号都被混淆成了由0oO随机排列的长度为24的命名,但是没有其他的混淆手段例如字符串加密或者控制流混淆,所以我们推测这个混淆是使用Proguard+字典混淆的,这相比其他混淆器例如ZKM的逆向难度要低很多,因为我们只需要简单推测语义就行了,不需要解密字符串等。
但是Proguard作为一个非常成熟的混淆器,重命名的覆盖面很广,其他混淆器会排除的Lambda方法、Enum、随机的接口等都被完全覆盖了,这实际上对我们的分析造成了一些阻碍,因为几乎没有任何地方泄露了原始的命名,甚至在他们的自定义工作流中native方法也在编译时适配的加持下被混淆了。
反编译一个随机Class,可以看到没有任何可用的符号
初步反混淆
要理解其语义,第一步其实是恢复SRG名,因为在forge的导出jar流程中,reobfJar任务会给Jar中的所有Minecraft引用的字段和方法名混淆,例如m_6259_,m_91404_这种无意义的命名。
手动修复这些东西是不现实的,首先我们需要获得这些mapping以便自动处理。在Setup了Forge 1.20.1 MDK之后打开everything搜索mapping,我们可以看到Forge Gradle将Mapping缓存到了mcp_repo文件夹中,这个zip中就包含了所有SRG名到MCP名的对照表。

但是这个Mapping并不能被Recaf的Mapping功能解析,所以我们需要自己写一个Remapper来实现,我们找到了java-deobfuscator/deobfuscator这个工具,可以轻松的创建自己的 transformer 处理 class,注册一个 transformer 然后遍历所有 MethodInsnNode 和 FieldInsnNode,读入 mapping 之后直接替换所有 name 即可,因为 srg 名不会变更 owner 和 desc。在输入 jar 并写出之后,成功恢复了所有 Minecraft 引用的命名。

反混淆
恢复了Minecraft引用的命名之后就可以开始反混淆jar本身了,但是jar中有超过1000个类需要反混淆,很显然不是所有类都是 YSM自己的,也有一些是 shadowJar 进去的 libs,在正式开始 remap 之前第一步是分离出这些 libs 。
Jar 中有一个 licenses 文件夹,包含了 YSM 使用的开源库的开源协议大全,但是很多都是 c/c++库,我们注意到其中的 concentus 和 opus 和 geckolib是 java 库,从 GitHub 下载源码之后,就可以使用 Matcher 完成分离了,Matcher 是一个 FabricMC推出的反混淆工具,可以通过分析类特征从不同版本的混淆 Jar 中分析命名,使用这个工具我们成功分离了 concentus 和 opus,但是我们注意到这个 geckolib 经过了大规模魔改,例如大部分 double 都被替换为了 float,所以这个暂时无法自动的分离。
现在还有超过 600 个类需要反混淆,其中不乏一些非常大的很复杂的类,手动反混淆 600 多个类显然不可能,我们需要一个自动化的反混淆方案。
我们最先注意到的方案是 IntelliJ IDEA 推出了 MCP 服务器可以重命名符号,但是这需要先反编译,但是目前的随机的 Oo0 组合的命名并不适合反编译,因为如果类名以 0 开头会被视为 error,而且也不适合随机 Remap 之后反编译,因为这样做可能会给以后 diff 原始 Jar 修复问题带来麻烦,所以我们最终放弃了这个方案。
在反编译前 Remap Jar 的最著名方案为 Enigma,可以直接 Remap Java 字节码并手动给每个符号命名,但是这款工具没有现有的自动化方案,所以我们需要 clone 源码研究自动化方案。
自动化Enigma
打开Enigma的源码,可以注意到Enigma有一个联机功能(Collab),允许多人协作联机Remap,我们可以借用这个系统为接口实现自动化接入。打开 Enigma-server 项目源码可以看到一个Protocol.md里面阐述了 Enigma 联机的协议结构,可以利用这个协议制作一个自动化客户端,自动的提交命名到 Enigma。
这个协议系统最大的好处就是可以直接从 Enigma 中接收聊天,可以利用这个来命令自动化客户端工作,照猫画虎写出 Enigma 协议客户端之后,就可以接入 Chat Completions API 实现调用 LLM 重命名了,使用 JSON output 功能可以让 LLM 输出标准的 json,然后自动解析这个 json 让 Enigma 协议客户端发包,即可完成自动化 Remap。
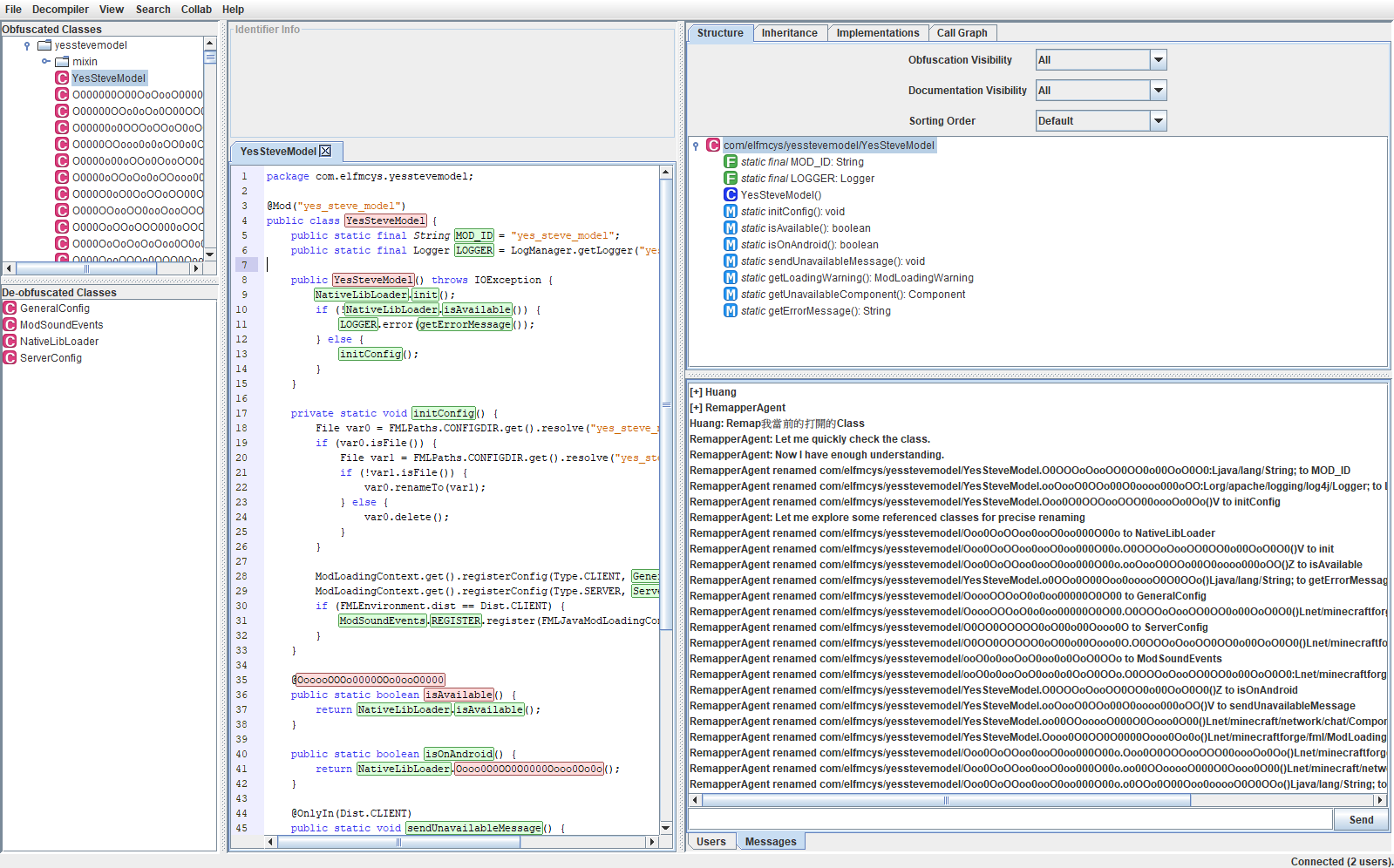
Remap geckolib和molang
Remap过程中我们发现LLM并不熟悉魔改的geckolib,我们需要找到一份可以参考的代码进行remap,然而我们发现这份魔改 geckolib 在 TartaricAcid 的另一个 mod TouhouLittleMaid中也有使用而 TouhouLittleMaid 是开源的,参考 TouhouLittleMaid 中的魔改 geckolib 源码我们即可手动修复 YSM 中的 geckolib 命名。
而 YSM 使用的 molang 解析器为 mocha,同样可以经过简单对比手动修复命名。
在这套步坦协同的方案执行完成之后,我们获得了恢复了所有语义命名的反混淆 Jar 文件,接下来使用 jadx 反编译即可。
反编译并且将源码放入 MDK 之后我们发现 YSM 添加了致死量的其他模组引用,因为 YSM 的封闭导致其他模组不能去兼容他,只能他来主动兼容其他模组。
在多个平台找到这些模组之后放进 libs,修复反编译错误导致的一些错误,我们就可以在 IDE 中启动 YSM 了,但是由于他的 native 中有 Jar 完整性检查,导致 native 加载失败,所以无法进入游戏。

还原Native
在成功反编译了 Java 层之后,我们需要开始还原 Native,很多 Native 方法其实是类似 J2C Native 混淆的模式,这种可以使用 hook 来还原。
编写一个 dll,使用 MinHook 来 Hook 所有 JNI 方法,并输出调用参数,尝试使用 Agentlib 加载之后,我们就可以看到所有 JNI 调用了,结合 IDA 解析了 JNI 头的伪代码查看即可还原 Native 和 Java 的交互逻辑。
初始化逻辑
第一个需要还原的 Native 方法为FMLClientSetupEvent下调用的初始化,但是这个方法几乎没有抓到 JNI 调用说明这是一个原生方法而不是 j2c 方法,经过观察包含一些 GL 常数所以应该是 GL 环境检查,在 Hook 了 GLFW 之后我们摸清了大概逻辑,这是一个检查 GL 环境的代码,如果成功返回 null 失败了则返回 Chat Component。
第一步:检测环境,如果以下调用任何一个是 null 都会直接算初始化失败
GetProcAddress(lwjgl_module,"Java_org_lwjgl_opengl_GL11C_nglTexImage2D__IIIIIIIIJ");
GetProcAddress(lwjgl_module,"Java_org_lwjgl_opengl_GL11C_nglTexSubImage2D__IIIIIIIIJ");
GetProcAddress(lwjgl_module,"Java_org_lwjgl_opengl_GL11C_glTexParameteri");
GetProcAddress(lwjgl_module,"Java_org_lwjgl_opengl_GL11C_glTexParameterf");
GetProcAddress(lwjgl_module,"Java_org_lwjgl_opengl_GL11C_glPixelStorei");
GetProcAddress(lwjgl_module,"Java_org_lwjgl_opengl_GL11C_nglGenTextures__IJ");
GetProcAddress(lwjgl_module,"Java_org_lwjgl_opengl_GL11C_nglDeleteTextures__IJ");
GetProcAddress(lwjgl_module,"Java_org_lwjgl_opengl_GL11C_glBindTexture");
第二步:检查GL_MAX_TEXTURE_SIZE
第三步:Shader 是否可用
还原代码如下:
public static Object nativeClientInit() {
try {
int maxTexSize = GL11.glGetInteger(GL11.GL_MAX_TEXTURE_SIZE);
if (maxTexSize <= 0) {
return Component.literal("YSM: OpenGL context not available");
}
try {
int testShader = GL20.glCreateShader(GL20.GL_VERTEX_SHADER);
if (testShader != 0) {
GL20.glDeleteShader(testShader);
}
} catch (Exception e) {
return Component.literal("YSM: GL20 (shaders) not available");
}
return null; // 成功
} catch (Exception e) {
return Component.literal("YSM Client Init Failed: " + e.getMessage());
}
}
渲染逻辑
还原初始化之后,接下来更大的挑战:所有模型的渲染逻辑都在Native层完成,Java 层只负责传参,真正的渲染工作全部由Native完成。
通过之前编写的 Hook,我们可以看到游戏在每一帧渲染玩家时都会调用一个特定的native方法,在IDA中定位到这个native方法的实现可以看到这是整个Native中最复杂的几个函数之一,清理了大量混淆之后还有 9000 行伪代码。
函数开头从传入的模型对象读取了一个long字段,然后用这个值作为 index 去一个全局 map 中查找对应的mesh数据。
auto mesh_it = g_mesh_map.find(mesh_native_ptr);
// ... shared_ptr::_Incref
_InterlockedIncrement((volatile long*)(mesh_inner + 8));
然后使用GetFloatField每次读取一个float字段并存入栈上的float数组,共读取了 16 次,结合字段引用不难推断这是在读取 Matrix4f 的十六个字段m00到m33。
接着又是9次类似的调用,根据入参顺序读取的是PoseStack.Pose.normal的矩阵。

接下来是一些剔除逻辑,应该是剔除渲染不需要的部分,这是用于优化渲染速度的,而且代码很复杂,我们暂时跳过,查看下面的真正的渲染代码,可以分为几个流程。
while (current_part < last_part) {
PerPartRenderData* render_data = ...;
uint64_t part_addr = parts_begin + 120 * current_part;
float* vertices = (float*)(g_vertex_buffer + 48 * current_part);
if (vertices[11] != 0.0f) {
// 渲染子部件
}
if (vertices[6] == 0 || vertices[7] == 0 || vertices[8] == 0) {
current_part += *(uint32_t*)(part_addr + 108);
// 跳过渲染
continue;
}
if (vertices[10] != 0.0f) {
// Transform
}
// 构建矩阵
current_part++;
}
vertices为一个 float 数组,这个float数组每个 part 占 12 个 float,但每个值代表什么完全没有名字。我们注意到vertices[6..8]被用于任何一个值为 0 来跳过整个part及其子部件,这个就有可能是 scale,因为 scale 为 0 才会消失,position 或者 color 都不会。
vertices[3..5]后面被*-0.0625f,0.0625f是Minecraft的像素转换常数,*负值说明这是pivot的3D世界空间到模型空间转换,所以这可能是pivot(Geometry格式就是这样处理的)。剩下的vertices[0..2]大概是position因为 transform 有调用,vertices[9..10]是 UV 偏移,vertices[11]作为 flag 位。
在拿到父骨骼Transform之后,函数从 vertices 中取出 pivot 和 scale,构建当前part的局部变换矩阵:
float px = vertices[3] * -0.0625f;
float py = vertices[4] * -0.0625f;
float pz = vertices[5] * -0.0625f;
__m128 local_col0 = _mm_set_ps(0, 0, 0, vertices[6]);
__m128 local_col1 = _mm_set_ps(0, 0, vertices[7], 0);
__m128 local_col2 = _mm_set_ps(0, vertices[8], 0, 0);
__m128 local_col3 = _mm_set_ps(1.0f, pz, py, px);
这一段差不多等价于Minecraft 的 ModelPart.translateAndRotate 中 translate 和 scale:
poseStack.translate(this.x / 16.0F, this.y / 16.0F, this.z / 16.0F);
poseStack.scale(sx, sy, sz);
然后是一段重复多次模式的算法,bone × local的矩阵乘法,0x00/0x55/0xAA/0xFF四个常数对应的二进制是 00_00_00_00、01_01_01_01、10_10_10_10、11_11_11_11,每两位一组指定从寄存器选哪个值,所以这四次 shuffle 的效果是把 local_col0 的四个分量分别广播成 {x,x,x,x}、{y,y,y,y}、{z,z,z,z}、{w,w,w,w} 四个向量。
__m128 xxxx0 = _mm_shuffle_ps(local_col0, local_col0, 0x00);
__m128 yyyy0 = _mm_shuffle_ps(local_col0, local_col0, 0x55);
__m128 zzzz0 = _mm_shuffle_ps(local_col0, local_col0, 0xAA);
__m128 wwww0 = _mm_shuffle_ps(local_col0, local_col0, 0xFF);
__m128 res_col0 = _mm_add_ps(
_mm_add_ps(_mm_mul_ps(render_data->pose_row0, xxxx0),
_mm_mul_ps(render_data->pose_row1, yyyy0)),
_mm_add_ps(_mm_mul_ps(render_data->pose_row2, zzzz0),
_mm_mul_ps(render_data->pose_row3, wwww0)));
虽然这段代码看着又臭又长但是其实是SIMD优化给算法铺平了导致的,实际上的等价代码就是一次矩阵的 mul 计算:
Matrix4f result = new Matrix4f(boneMatrix).mul(localMatrix);
然后就是写回骨骼缓存,计算完的bone * local不仅会用于当前part的渲染,还会被写回到骨骼缓存中,供下一次循环找父骨骼Transform,同时还保存了可见状态,如果父骨骼不可见子骨骼也会被一起跳过渲染。
*(__m128*)(cache_entry + 0) = render_data->pose_row0;
*(__m128*)(cache_entry + 16) = render_data->pose_row1;
*(__m128*)(cache_entry + 32) = render_data->pose_row2;
*(__m128*)(cache_entry + 48) = render_data->pose_row3;
memcpy(cache_entry + 64, &render_data->normal_mat, 36);
*(float*)(cache_entry + 96) = render_data->det_sign;
这些完成之后通过VertexConsumer提交,完成顶点构建。
这一套渲染流程中大部分矩阵方法在 joml 中都有 Java 实现,或者说YSM 的 C++渲染也是从 Java 翻译而来,总之翻译回 Java 并不复杂,还有 joml 中的方法可以复用。
至于剔除算法,我们可以自己实现一个在 Java 中。
模型加载
对于模型加载,LgeacyYSM(不是 Legacy)有很大的参考价值,对于几个 ModelManager 也可以直接复用部分代码,只需要完善新格式适配即可。
然后这个 native 方法的骨架其实很简单:把三个接受的 JNI 参数(path、hash、consumer)各自包装成一个native pointer,组装成一个加载任务,然后提交到后台线程池。
void* task = ysm_alloc(64);
*(void**)((uint8_t*)task + 0) = path_wrapper;
*(void**)((uint8_t*)task + 8) = hash_wrapper;
*(void**)((uint8_t*)task + 16) = consumer_wrapper;
submit_load_task(dispatcher, task);
所以我们需要追踪到他实际的 Worker,Worker 方法是一个比渲染还要大的复杂方法,我们逐步开始分析。
对开头进行分析之后,其实是一些 flag 检查确保现在只有一个模型在加载。然后从全局获取 Mod 的加载状态,检查是否设置了 shutdown 标志(如果 Mod 正在卸载就直接退出回调)。
然后按 hash 去重,避免重复加载已经加载过的模型,接下来就进入主要文件操作逻辑了,大概流程是这样的:
- 用
filesystem::status检查文件状态 - 通过
fs_path_extension获取扩展名 - 不区分大小写比较是否为.ysm
- 如果是 YSM 格式则会进入
sub_7FFD6D5FFA20也就是解密逻辑 - 如果不是 YSM 则继续加载
- 如果是 YSM 格式则会进入
- 把文件读到std::vector<uint8_t>
- 如果文件为空,尝试删除
- 然后进入加载逻辑
对于加密的 YSM 模型,我们早在制作 YSMParser 时候就已经完全理解了,所以我们可以轻松的移植过来,而加载逻辑可以复用 LegacyYSM 中的代码。
至此所有关键的 Native 方法都已经实现,剩下的小方法基本都是这些大方法的辅助函数,而其他方法大部分都是简单的 JNI 调用包装(例如网络部分),推测是只是用于混淆性质让自己的 Native 方法看着多一点罢了,直接使用 JNI Hook 配合简单的静态分析即可全部复刻。
Native 代码的复杂度有相当一部分并非来自真正的算法复杂性,而是来自用C++手动实现Java中现有的库的逻辑,比如 joml,Map 等,剥离这些障眼法之后,就可以很容易的恢复为 Java 代码。
将这些 Native 方法实现之后,成功启动并进入游戏
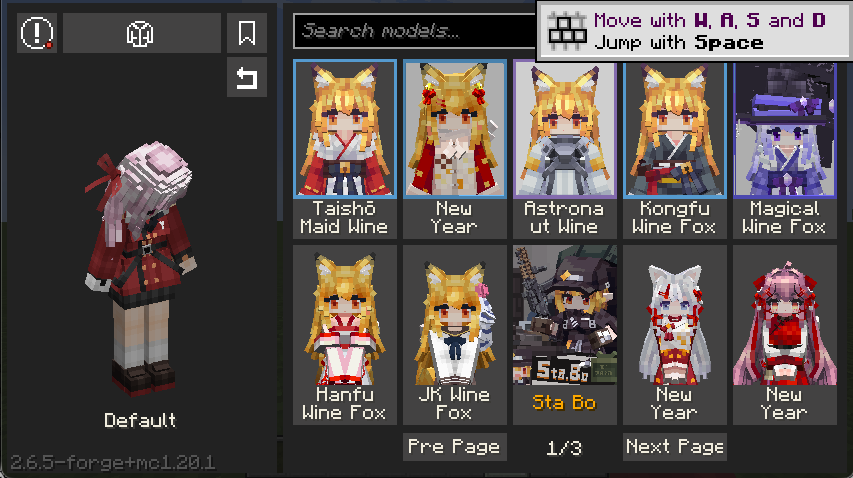
研究成果
经过这次完整的逆向分析,我们获得了以下成果:
我们几乎恢复了全部的语义命名,甚至已经到了可以持续维护和开发的程度,我们也开源了这个项目,作为一份礼物送给我们的支持者和社区。
所有Native方法用纯Java重新实现并集成到完整的Mod中,在没有原始DLL的情况下能够正常启动并进入游戏,模型可以正常加载和渲染。这意味着YSM的Native保护层在功能层面已经完全失效。同时我们也解决了 YSM 一直没有解决的兼容性问题,无论是被清退的 MacOS,从未被支持过的 RISC-V,甚至是手机上也可以运行,兼容性远超原版 YSM,可以说只要可以运行 Minecraft,就能运行我们的 OpenYSM。